




The Kubernetes journey so far
In the first week of June 2021 the Kubernetes project will turn 7 years old. But why this project was started by Google? What problems they wanted to solve with the help of this?
Tech giant Google in 2003-04 started a project called Borg System. It was a large-scale internal cluster management system. It was designed to serve huge workloads for example running thousands of jobs, for different applications, across many clusters and thousands of servers.
Starting with Borg and later Omega Google finally in mid 2014 introduced the Project Kubernetes and released it as an open source version of Borg.
Within few months of initial release companies like Microsoft, RedHat, IBM and Docker joined the Kubernetes community.
Within a year the Kubernetes version 1.0 was released and later it was donated to the Cloud Native Computing Foundation by Google.
What is Kubernetes?
It's an open source container orchestration platform that helps manage distributed, containerized applications at a massive scale. It was designed to run enterprise-class, cloud-enabled and web-scalable IT workloads.
Kubernetes has now become one of the hottest technology in the IT world and every enterprise today wants to leverage the same within their infrastructure.
Most of the companies if not all directly or indirectly have their workloads hosted over Kubernetes.
Why Kubernetes is so hot?
Though its popularity is mostly a recent trend, the concept of containers has existed for over a decade. But it was Docker which has demonstrated that containerization can drive the scalability and portability of applications for development and IT operations teams. They have become an integral part of build automation and continuous integration and continuous deployment (CI/CD) pipelines.
The solutions that are already containerized can drastically reduce development time spent on operations and deployment.
It speeds up the overall software and application development process by making easy, faster, automated deployments, updates to running applications with almost zero downtime.
What can be achieved by using Kubernetes
- It provides auto-scalable containerized infrastructure
- It provides Application-centric management
- Highly available distributed system
- It is made to be portable, enable updates with near-zero downtime, version rollbacks.
- Clusters with ‘self-healing’ capabilities when there is a problem
- Load balancing, auto-scaling and SSL can easily be implemented
- Environment consistency across development testing and production
- Loosely coupled infrastructure, where each component can act as a separate unit
One of the key components of Kubernetes is, it can run application on clusters of physical, virtual and cloud infrastructure as well. It helps in moving from host-centric infrastructure to container-centric infrastructure.
Kubernetes Architecture
Kubernetes follows client-server architecture. Wherein, we have master installed on one machine and the worker nodes on separate Linux machines.

Kubernetes has a decentralized architecture that does not handle tasks sequentially. It functions based on a declarative model and implements the concept of a desired state.
Following steps illustrate the basic Kubernetes process:
An administrator creates and places the desired state of an application into a manifest file.
The file is provided to the Kubernetes API Server using a CLI or UI. Kubernetes default command-line tool is known as
kubectl.
Kubernetes stores the file (an application’s desired state) in a database called the Key-Value Store (etcd).
Kubernetes then implements the desired state on all the relevant applications within the cluster.
Kubernetes continuously monitors the elements of the cluster to make sure the current state of the application does not vary from the desired state.
Master Node (Control Plane) and its components
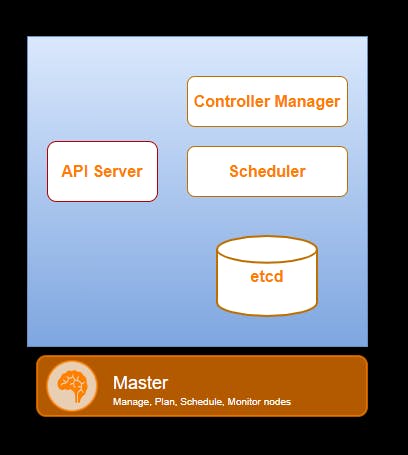
The Kubernetes Master receives input from CLI or UI via an API. These are the commands which you provide to Kubernetes. The master node is the main entry point for all administrative tasks you want to perform on the cluster. It controls all the worker nodes.
You define pods, replica sets, and services that you want Kubernetes to maintain. For example what container image to use, which ports to expose, and how many pod replicas to run etc..
You also provide the parameters of the desired state for the application(s) running in that cluster.
Kube-API Server
The Kube-API Server is the front-end of the control plane and the only component in the control plane that we interact directly with. Internal system components, as well as external user components, all communicate via the same API.
Key-Value Store (etcd)
The Key-Value Store, also called etcd, is a database Kubernetes uses to back-up all cluster data. It stores the entire configuration and state of the cluster. The Master node queries etcd to retrieve parameters for the state of the nodes, pods, and containers.
Controller Manager
The role of the Controller is to obtain the desired state from the API Server. It checks the current state of the nodes it is tasked to control, and determines if there are any differences, and resolves them, if any.
Scheduler
A Scheduler watches for new requests coming from the API Server and assigns them to healthy nodes. It ranks the quality of the nodes and deploys pods to the best-suited node. If there are no suitable nodes, the pods are put in a pending state until such a node appears.
Worker Node and its components
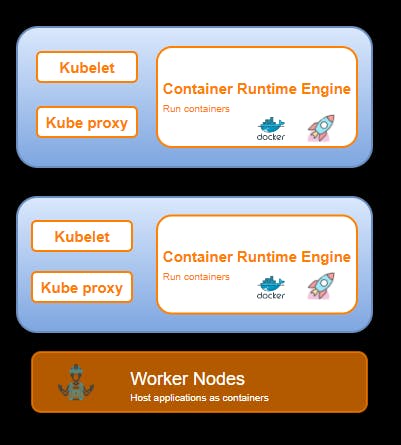
Worker nodes listens to the API Server for new work assignments. They execute the work assignments and then report the results back to the Kubernetes Master node. Each worker node is controlled by the Master Node.
Kubelet
The kubelet runs on every node in the cluster. It is the principal Kubernetes agent. It interacts with etcd store to read configuration details and write values. It watches for tasks sent from the API Server, executes the task, and reports back to the Master. It also monitors pods and reports back to the control panel if a pod is not fully functional. Based on that information, the Master can then decide how to allocate tasks and resources to reach the desired state.
Container Runtime
The container runtime pulls images from a container image registry and starts and stops containers. A 3rd party software or plugin, such as Docker, usually performs this function.
Kube-proxy
The kube-proxy makes sure that each node gets its IP address, implements local iptables and rules to handle routing and traffic load-balancing. This ensures that the necessary rules are in place on the worker nodes to allow the containers running on them to reach each other.
Pod
A pod is the smallest element of scheduling in Kubernetes. Without it, a container cannot be part of a cluster. If you need to scale your app, you can only do so by adding or removing pods. It is possible to create a pod with multiple containers inside it. The pod serves as a ‘wrapper’ for a single container with the application code. Based on the availability of resources, the Master schedules the pod on a specific node and coordinates with the container runtime to launch the container.
You should now have a better understanding of Kubernetes architecture and can proceed with the practical task of creating and maintaining your clusters.
Key benefits of using Kubernetes
Portability
Kubernetes offers portability, and faster, simpler deployment times. This means that companies can take advantage of multiple cloud providers if needed and can grow rapidly without having to re-architect their infrastructure.
Scalability
With Kubernetes ability to run containers on one or more public cloud environments, in virtual machines, or on bare metal means that it can be deployed almost anywhere.
High Availability
Kubernetes addresses high availability at both the application and the infrastructure level. Adding a reliable storage layer to Kubernetes ensures that stateful workloads are highly available. In addition to this, the master components of a cluster can be configured for multi-node replication (multi-master) and this also ensures a higher availability.
Open Source
Since Kubernetes is open source, you can take advantage of the vast ecosystem of other open source tools designed specifically to work with Kubernetes without the lock-in of a closed/proprietary system.
Proven, and Battle Tested
A huge ecosystem of developers and tools with 17000 plus GitHub repositories and counting means that you won’t be forging ahead into new territory without help.
Market Leader
It was developed by and used and maintained by Google which not only gives it instant credibility, but can be trusted to fix bugs and release new features on a regular basis.
So that brings an end to this blog on Kubernetes Architecture. Hope you like it. Do look out for other blogs in this series which will explain the various other aspects of Kubernetes.
Stay Tuned and don't forget to provide your feedback in the response section.
Thank you. Happy learning!